分布式共识及算法
分布式系统中充满了各种潜在的错误场景,网络数据包可能丢失、顺序紊乱、重复发送或者延迟,节点还可能宕机。“在充满不确定性的环境中,就某个决策达成共识”是软件工程领域最具挑战性的问题之一。
什么是共识
在分布式系统中,节点故障不可避免,但部分节点故障不应该影响系统整体状态。通过增加节点数量,依据“少数服从多数”原则,只要多数节点(至少 N/2+1N/2+1)达成一致,其状态即可代表整个系统。这种依赖多数节点实现容错的机制称为 Quorum 机制。
Quorum 机制
- 3 节点集群:Quorum 为 2,允许 1 个节点故障;
- 4 节点集群:Quorum 为 ⌈4/2⌉+1=3⌈4/2⌉+1=3,允许 1 个节点故障;
- 5 节点集群:Quorum 为 ⌈5/2⌉+1=3⌈5/2⌉+1=3,允许 2 个节点故障。
节点个数为 NN 的集群,能容忍 (N−1)/2(N−1)/2 个节点故障。你注意到了么?3 节点和 4 节点集群的故障容忍性一致。所以,一般情况下,以容错为目的的分布式系统没必要使用 4 个节点。
根据上述的讨论,基于 Quorum 的机制,在不可靠的环境下,通过“少数服从多数”协商机制达成一致的决策,从而对外表现为一致的运行结果。这一过程被称为节点间的“协商共识”。
一旦解决共识问题,便可提供一套屏蔽内部复杂性的抽象机制,为应用层提供一致性保证,满足多种需求,例如:
主节点选举:在主从复制数据库中,所有节点需要就“谁来当主节点”达成一致。如果由于网络问题导致节点间无法通信,很容易引发争议。若争议未解决,可能会出现多个节点同时认为自己是主节点的情况,这就是分布式系统中最棘手的问题之一 —— “脑裂”。
原子事务提交:对于支持跨节点或跨分区事务的数据库,可能会发生部分节点事务成功、部分节点事务失败的情况。为维护事务的原子性(即 ACID 特性),所有节点必须就事务的最终结果达成一致。
分布式锁管理:当多个请求尝试访问共享资源时,共识机制可确保所有节点一致认定“谁成功获取了锁”。即使发生网络故障或节点异常,也能避免锁争议,从而防止并发冲突或数据不一致。
日志复制:日志复制指将主节点的操作日志同步到从节点。在这一过程中,所有节点必须确保日志条目的顺序一致,即日志条目必须以相同顺序写入。
日志与复制状态机
这里提到的“日志”,并不是常见的通过 log4j 或 syslog 输出的文本。而是 MySQL 中的 binlog(Binary Log)、MongoDB 中的 Oplog(Operations Log)、Redis 中的 AOF(Append Only File)、PostgreSQL 中的 WAL(Write-Ahead Log)…。这些日志名称不同,但它们的共同特点是只能追加、完全有序的记录序列。
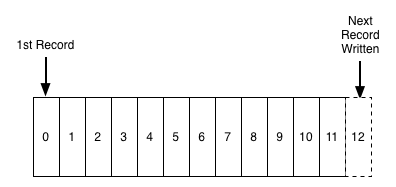
上图展示了日志结构,日志是有序的、持久化的记录序列,在末尾追加记录,读取时则从左到右顺序扫描。
有序的日志记录了“什么时间发生了什么”,这句话的含义通过下面两种数据复制模型来理解:
主备模型(Primary-backup):也称“状态转移”模型,主节点(Master)负责执行如“+1”、“-2”的操作,将操作结果(如“1”、“3”、“6”)记录到日志中,备节点(Slave)根据日志直接同步结果;
复制状态机模型(State-Machine Replication):也称“操作转移”模型,日志记录的不是最终结果,而是具体的操作指令,如“+1”、“-2”。这些指令按照顺序被依次复制到各个节点(Peer)。如果每个节点按顺序执行这些指令,各个节点将最终达到一致的状态。
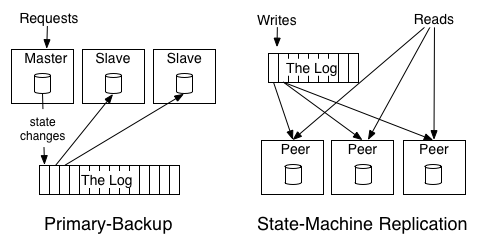
无论哪一种模型,它们都揭示了:“顺序是节点之间保持一致性的关键因素”。如果打乱了操作的顺序,就会得到不同的运算结果。
共识算法(是 Paxos 或者 Raft 算法)以消息的形式将日志广播至所有节点,它们就日志什么位置,记录什么(序号为 9,执行 set x=3)达成共识。也就说,每一台节点都有着相同顺序的日志序列,日志按一个全局的时序顺序执行,并且每个操作看起来是原子发生的。
Paxos 算法
在 Paxos 算法中,节点分为三种角色:
提议者(Proposer):提议者是启动共识过程的节点,它提出一个值,请求其他节点对这个值进行投票,提出值的行为称为发起“提案”(Proposal),提案包含提案编号 (Proposal ID) 和提议的值 (Value)。
决策者(Acceptor):接受或拒绝提议者发起的提案,如果一个提案被超过半数的决策者接受,意味着提案被“批准”(accepted)。提案一旦被批准,意味着在所有节点中达到共识,便不可改变、永久生效。
记录者(Learner):记录者不发起提案,也不参与决策提案,它们学习、记录被批准的提案。
在 Paxos 算法中,节点都是平等的,它们都可以承担一种或者多种角色。
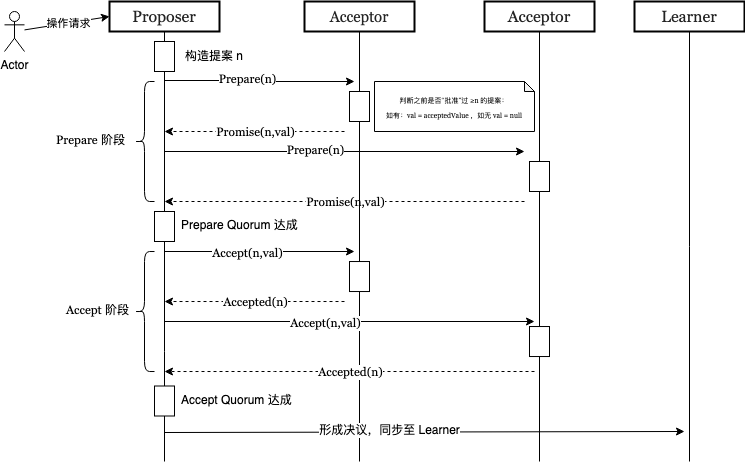
Paxos 算法的第一个阶段称“准备阶段”(Prepare)。提议者选择一个提案编号 N(通常是单调递增的数字,相当于乐观锁中的 version,更高的编号意味着更高的优先级),向所有的决策者广播许可申请(称为 Prepare(N) 请求),如果决策者:
- 尚未承诺 ≥N 编号的提案:则“承诺”(promise)不再接受任何编号小于 NN 的提案,返回一个响应,其中包含承诺的提案编号以及对应的提案值(如果有);
- 已承诺 ≥N 编号的提案:拒绝 Prepare 请求,不返回任何响应。
完成以上操作后,进入下一个阶段。
Paxos 算法的第二个阶段称“批准阶段”(Accept)。提议者向所有决策者广播批准申请。如果决策者发现提案编号 N ≥ 它已承诺的最大编号,则“批准”(accepted)该提案;否则拒绝该提案。
当多数的决策者批准提案时,提议者认为本轮提案成功、共识达成。一旦提案成功,提议者会将最终的决议广播给所有记录者节点,供它们学习、记录最终结果。
Paxos算法的价值和缺憾
Paxos 的价值在于推动了分布式共识算法的发展,但它有以下缺陷:
- 只能处理单一提案,且达成共识至少需要两次网络往返;
- 高并发情况下可能导致活锁;
Lamport 在论文《Paxos Made Simple》中提出了 Paxos 的优化变体 —— Multi Paxos。Multi Paxos 引入了“选主”机制,通过多次运行 Paxos 算法来处理多个提案。不过,Lamport 的论文主要关注的是 Paxos 的算法基础和正确性证明,对于领导者选举以及解决多轮提案的效率问题,并没有给出充分的实现细节。2014 年,斯坦福的学者 Diego Ongaro 和 John Ousterhout 发表了论文《In Search of an Understandable Consensus Algorithm》,该论文基于 Multi Paxos 思想,提出了“选主”、“日志复制”等概念及其实现细节,提出了简化和改进版的 Raft 算法。
Raft算法
Paxos 算法中“节点众生平等”,每个节点都可以发起提案。多个提议者并行发起提案,是活锁、以及其他异常问题的源头。那如何不破坏 Paxos 的“节点众生平等”基本原则,又能在提案节点中实现主次之分,限制节点不受控的提案权利?
Raft 算法的设计机制是明确领导者、增加选举机制交接提案权利。Raft 算法中,节点分为以下三种角色:
领导者(Leader):负责处理所有客户端请求,将请求转换为“日志”复制到其他节点,不断地向所有节点广播心跳消息:“你们的领导还在,不要发起新的选举”。
跟随者(Follower):接收、处理领导者的消息,并向领导者反馈日志的写入情况。当领导者心跳超时时,他会主动站起来,推荐自己成为候选人。
候选人(Candidate):候选人属于过渡角色,他向所有的节点广播投票消息,如果他赢得多数选票,那么他将晋升为领导者;
联想到现实世界中的领导人都有一段不等的任期。自然,Raft 算法中也对应的概念 —— “任期”(term)。Raft 中的任期是一个递增的数字,贯穿于 Raft 的选举、日志复制和一致性维护过程中。
选举过程:任期确保了领导者的唯一性。在一次任期内,只有获得多数选票的节点才能成为领导者。
日志一致性:任期号会附加到每条日志条目中,帮助集群判断日志的最新程度。
冲突检测:通过比较任期号,节点可以快速判断自己是否落后,并切换到跟随者状态。
4.1 领导者选举
概述了 Raft 集群 Leader 选举过程:
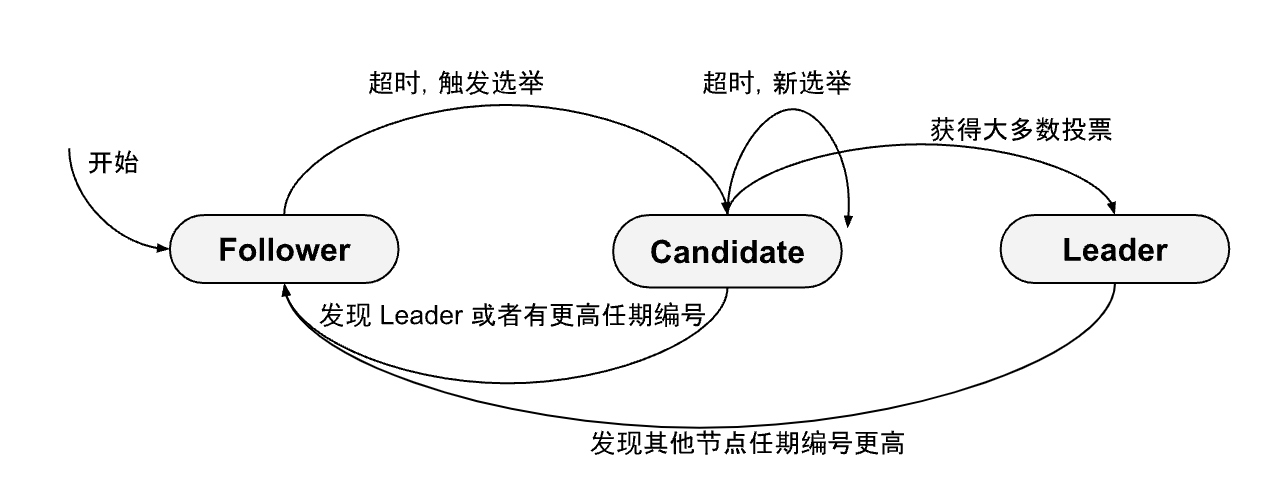
首先,初始状态下,所有的节点处于跟随者状态。因为集群中还没有领导者,某个跟随者未在选举超时时限内(通常是 150-300 毫秒的随机超时时间)收到领导者的心跳,该节点触发选举。节点的角色从跟随者转为 候选者。候选者增加自己的任期号,向其他节点广播“投票给我”的消息(RequestVote RPC)。
RequestVote RPC 消息示例如下:
1 | |
节点收到投票消息后,根据以下条件判断是否投票:
- 候选者的日志至少与投票者的日志一样新(根据最后一条日志的任期号和索引号判断)。
- 当前节点尚未在本任期投票。
RequestVote 响应的示例如下:
1 | |
如果候选者获得多数(超过半数)节点的投票,即成为领导者。之后,领导者向其他节点广播心跳消息,维持领导者地位。如果没有获得多数票,进入下一轮选举,任期递增,重新发起投票。如果在选举过程中收到任期号更高的心跳或投票请求,转为跟随者。
4.2 日志复制
一旦选出一个公认的领导者,那领导者顺理其章地承担起“处理系统发生的所有变更,并将变更复制到所有跟随者节点”的职责。
在 Raft 算法中,日志承载着系统所有变更。每个“日志条目”(log entry)包含索引、任期、指令等关键信息:
- 指令: 表示客户端请求的具体操作内容,也就是待“状态机”(State Machine)执行的操作。
- 索引值:日志条目在仓库中的索引值,是单调递增的数字。
- 任期编号:日志条目是在哪个任期中创建的,用于解决“脑裂”或日志不一致问题。
Raft 算法中,领导者通过广播消息(AppendEntries RPC)将日志条目复制到所有跟随者。AppendEntries RPC 的示例如下:
1 | |
当 Raft 集群收到客户端请求(例如 set x=4)时,日志复制的过程如下:
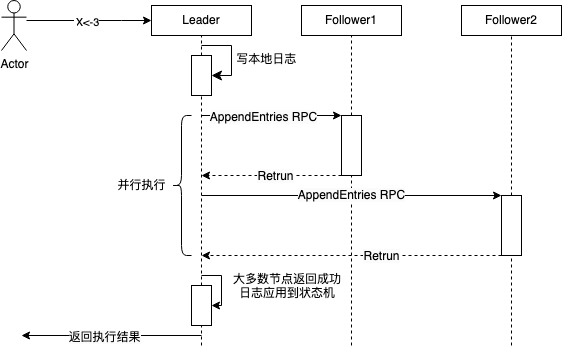
- 如果当前节点不是领导者,节点将请求转发给领导者;
- 领导者接收请求后:
- 将请求转化为日志条目、写入本地仓库,日志条目初始状态为“未提交”(uncommitted);
- 生成一条日志复制消息(AppendEntries RPC),广播给所有的跟随者;
- 跟随者收到志复制消息后,检查任期(如本地任期是否比领导者任期大)、检查日志一致性(根据 prevLogIndex 判断日志是否缺失)。如果检查通过,跟随者将新的日志条目追加到自身的日志中,并发送确认响应。
- 当领导者发现某个日志条目已经在多数节点上复制成功后,将该日志条目标记为“已提交”(committed),并向客户端返回执行结果。已提交的日志意味着:日志不可回滚,指令永久生效,可安全地“应用”(apply)到状态机。
领导者向客户端返回结果,并不代表日志复制过程已经完成,因为跟随者尚不清楚日志条目是否已被大多数节点确认。Raft 的设计通过心跳或后续日志复制请求中携带更新的提交索引(leaderCommit),通知跟随者提交日志。这样的设计将“达成共识的过程”优化为一个阶段,减少了客户端约一半的等待时间。
我们来看日志复制的另一种情况。在上述例子中,只有 follower-1 成功追加日志,这是因为 follower-2 的日志并不连续。日志的连续性至关重要,因为如日志条目没有按正确顺序应用到状态机,各个 follower 节点的状态肯定不一致。
当 follower-1 收到日志复制请求后,它会通过 prevLogIndex 和 prevLogTerm 检查本地日志的连续性。如果日志缺失或存在冲突,follower-2 会返回失败响应,指明与领导者日志不一致的部分。
1 | |
当领导者收到失败响应,根据 conflictIndex 和 conflictTerm 找到与跟随者日志的最大匹配索引。随后,领导者从该索引开始重新向跟随者(如 follower-1)发送日志条目,逐步修复日志的不一致性,直至同步完成。
【出处】